





Nếu bạn gặp các trường hợp sau thì bạn tìm đúng nơi rồi đó:
Khi nghe các anh senior chém gió. Các ảnh hay chêm mấy câu Tiếng Anh vào. Và bạn không hiểu gì hết. Ví dụ: Trước đây anh có design một high availability system. Cũng căng thẳng lắm em. Anh phải kiểm soát latency chặt chẽ lắm.
Hoặc khi các bạn học các khóa học (có thể là English) hoặc đọc các bài báo, technical blog. Mà gặp các từ ngữ không hiểu gì hết, điều này rất khó chịu phải không?
Mình cũng hiểu được vấn đề này nên quyết định viết một vài bài về các thuật ngữ trong system design (sau này sẽ đi sâu hơn nữa) để cho các bạn mới bắt đầu tìm hiểu sẽ dễ dàng hơn và không nản. Vì đây là môt topic khó, đòi hỏi hiểu biết rất nhiều.
Và mục tiêu của mình là sau bài viết các bạn sẽ "sướng hơn" khi gặp 2 trường hợp ví dụ trên. Trình độ của bạn cũng sẽ lên rất nhanh đó.
Vào việc, từ đầu tiên!
Latency - độ trễ
"Em ơi, anh tới rồi nè, em xong chưa?"
Và cô ấy trả lời bạn "Dạ anh đợi em 5p em đang thay đồ".
Two hours later...
Và 2 tiếng chờ đợi bạn gái của bạn chính là latency. Ban đầu bạn expect 5p thôi, nhưng kết quả "hệ thống" của bạn khá, à không rất chậm nên cho latency cao. Chắc đang bị ... gì đó, thắt cổ chai chăng =)).
Latency là thời gian chờ đợi khi gửi một tín hiệu hoặc yêu cầu từ một thiết bị đến thiết bị khác và khi nhận được phản hồi hoặc kết quả. Đây là thời gian mà tín hiệu đi qua các mạng và các thiết bị trung gian trước khi đến đích.
Và quay trở lại công việc một backend developer.
Khi bạn được giao thiết kế một API. Latency bạn có thể hiểu đơn giản là thời gian response của một API.
Khi bạn implement xong, trong một số công ty bạn sẽ phải thực hiện đo latency của API đó. Hoặc một team khác làm, team performance chẳng hạn.
Ví dụ bạn rule team bạn là. Làm sao làm, thời gian reponse của API không được quá 100ms. Thì bạn và team sẽ phải tìm cách tối ưu để latency đạt yêu cầu. Ví dụ tối ưu câu query, ...
Distributed database - cơ sở dữ liệu phân tán
Đơn giản dễ hiểu như thế này. Hệ thống của bạn có nhiều con server chứa dữ liệu (khác IP address) thì mình gọi là distributed database. Hay còn gọi là database phân tán.
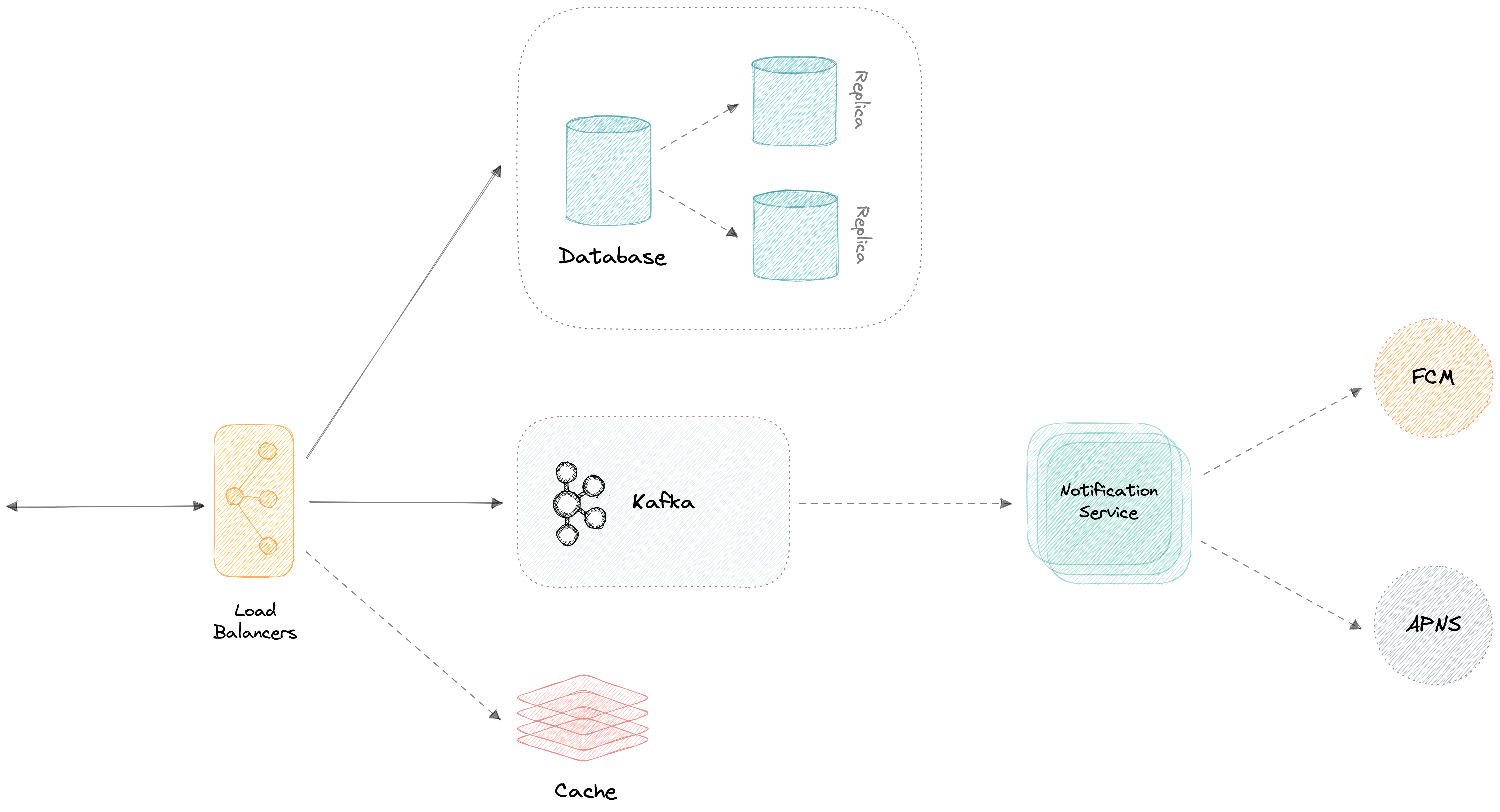
Trên hình có 1 con database Cache (Redis chẳng hạn). Và một cụm 3 con database relational (MySQL chẳng hạn). Vậy thì hệ thống ở trên chính là distributed database. Bạn chỉ cần hiểu đơn giản vậy là được rồi.
Distributed database có rất nhiều pattern để triển khai. Mình sẽ không đề cập tất cả ở đây nha. Chỉ lướt qua một số thôi.
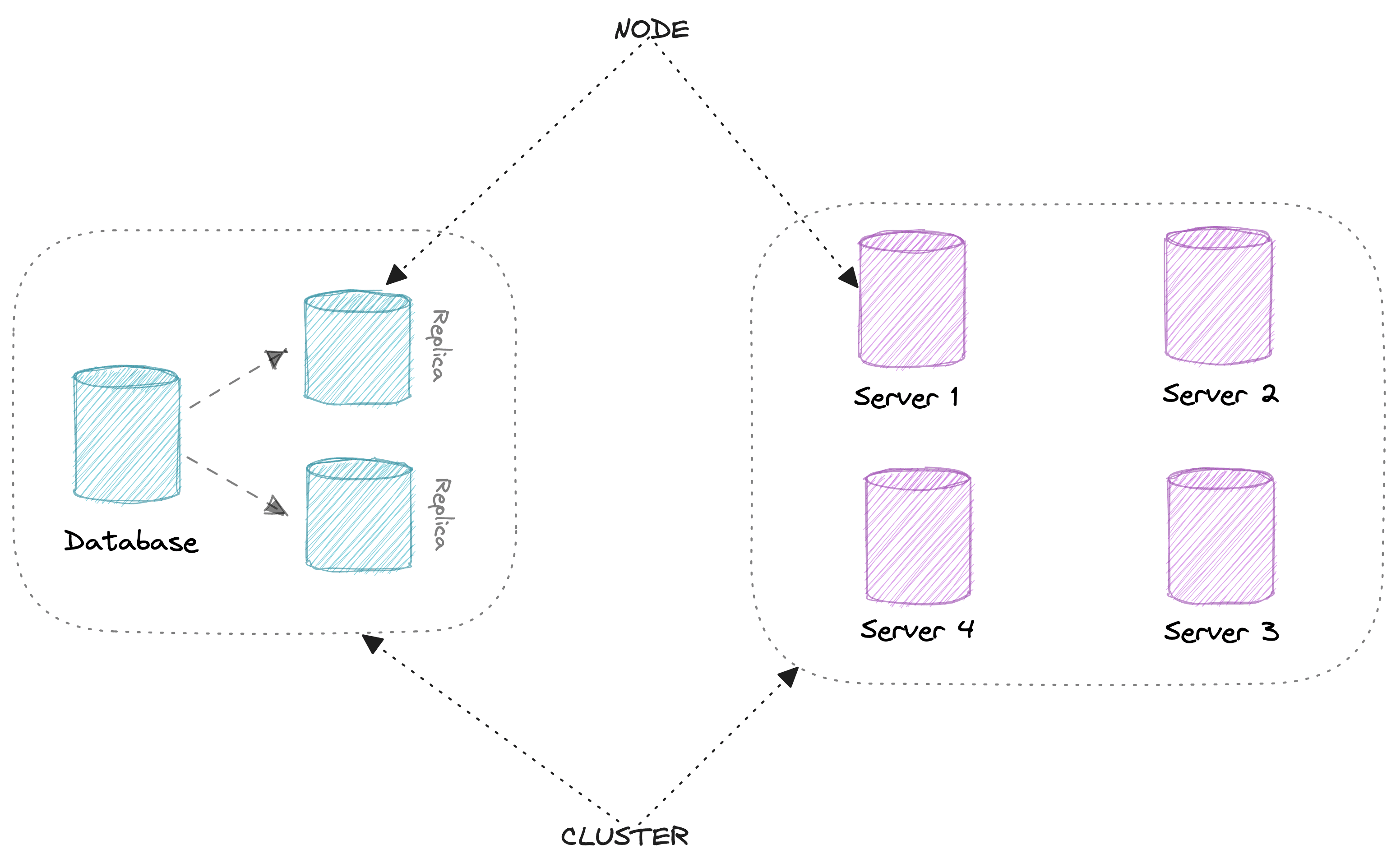
Và trong distributed database có 2 khái niệm mình muốn các bạn nắm:
- Cluster: một cụm các con servers
- Node: một con server trong một cụm cluster
Nhìn cái hình nha.
Replication
Replication nghĩa là copy. Khi bạn lưu dữ liệu trên một con database, sau đó dữ liệu được copy ra một hoặc một vài con server khác thì gọi là replication.
Replication có 2 pattern thông dụng và người ta rất hay xài:
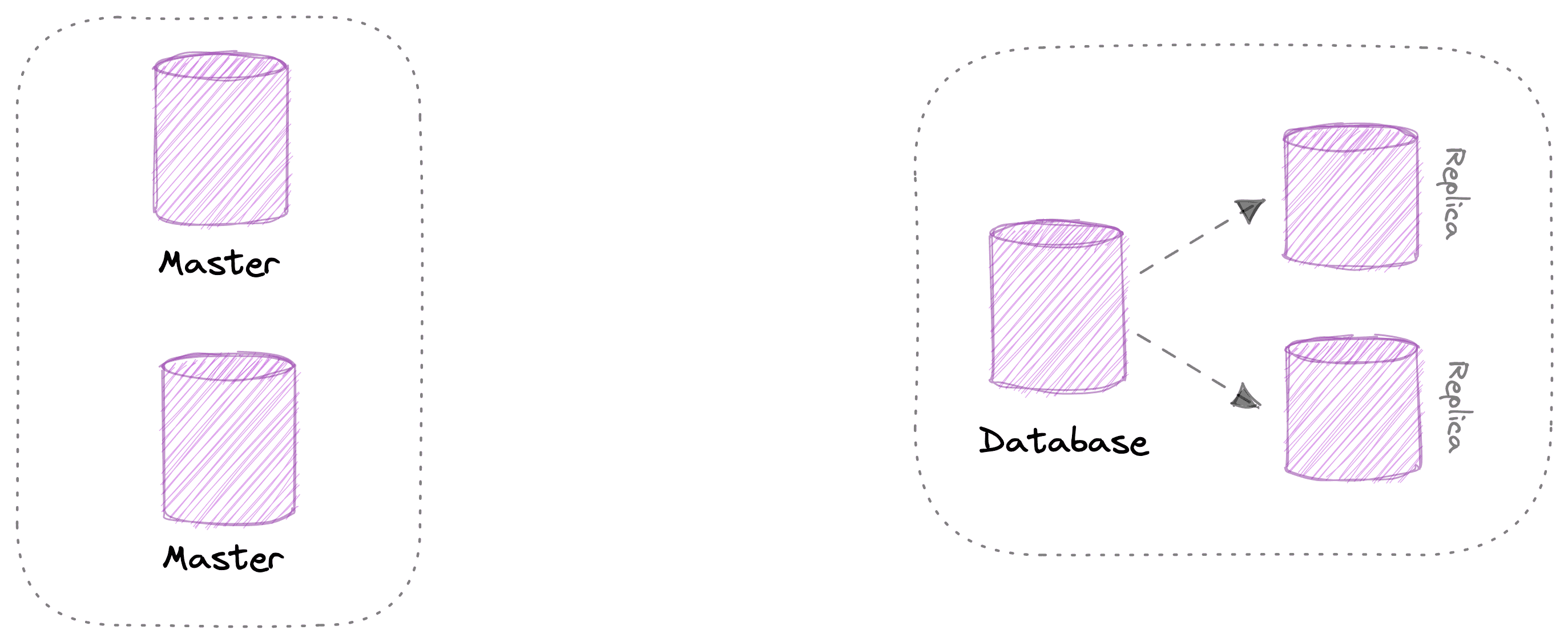
- Master – master: lúc này bạn có hai con server ngang hàng nhau, chia tải cho nhau. Và cùng làm luôn nhiệm vụ đọc và ghi luôn. Mục tiêu người ta hay dùng pattern mà mình hay thấy là chia tải cho database (tránh tình trạng tắt nghẽn do có quá nhiều request). Thứ 2 là làm nhiệm vụ backup, khi server database tạch thì có con backup để toàn vẹn dữ liệu.
- Master – slave: pattern này các bạn sẽ thấy khá nhiều nơi áp dụng. Thông thường thì con master sẽ làm nhiệm vụ ghi dữ liệu. Còn đọc dữ liệu sẽ là các con slave (đôi khi có thể đọc luôn ở con master – tùy vào team của bạn). Mục tiêu của pattern này cũng tương tự như pattern trên thôi, cũng là chia tải và làm nhiệm vụ backup.
Và bạn lưu ý là dữ liệu của các con server này là giống nhau nha. Bạn hãy nhìn hình sau để hiểu rõ hơn ha. Bên trái là master-master, bên phải là master-slave.
Replication khá là đơn giản thôi các bạn. Nhưng trên thực tế triển khai sao cho tối ưu và phù hợp với business của cty bạn thì không đơn giản. Ví dụ làm sao để sync dữ liệu giữa các con server này với nhau. Rồi có khi nào nó sync bị tạch không? Hoặc chưa kịp sync thì có request read dữ liệu, dẫn tới đọc dữ liệu cũ hay không? … Túm lại là có rất nhiều vấn đề khi triển khai các cụm cluster replication.
Sharding và những thứ xung quanh nó
Vẫn là dữ liệu được nằm trên nhiều con server khác nhau. Nhưng lần này dữ liệu không còn giống nhau nữa (giống nhau là replication). Chúng ta gọi nó là sharding.
Mình lấy ví dụ, bây giờ hệ thống của bạn có một con database chứa user (user service). Nhưng do bây giờ user nhiều quá, lượng request cũng nhiều nữa. Bạn muốn tách ra thành nhiều server, mỗi server chứa một ít dữ liệu cho dễ quản lý và tăng khả năng chịu tải của database. Và lúc này, bạn có thể scale độc lập cho từng node trên cluster trên. Ví dụ database 1 lượng truy cập là nhiều nhất, bạn cho node này nhiều Ram, CPU nhất.
Và sau nhiều đêm trằn trọc, với trí thông minh của một thiên tài, bạn quyết định tách thành 4 con server như sau:
- Database 1: lưu các users có ID chia cho 4 dư 1 (mod). Ví dụ 1, 5, 9, 13, …
- Database 2: lưu các users có ID chia cho 4 dư 2. Ví dụ 2, 6, 10, 14, …
- Database 3: lưu các users có ID chia cho 4 dư 3. Ví dụ 3, 7, 11, 15, …
- Database 4: lưu các users có ID chia cho 4 dư 0. Ví dụ 4, 8, 12, 16, …
Xem hình bên dưới nha.
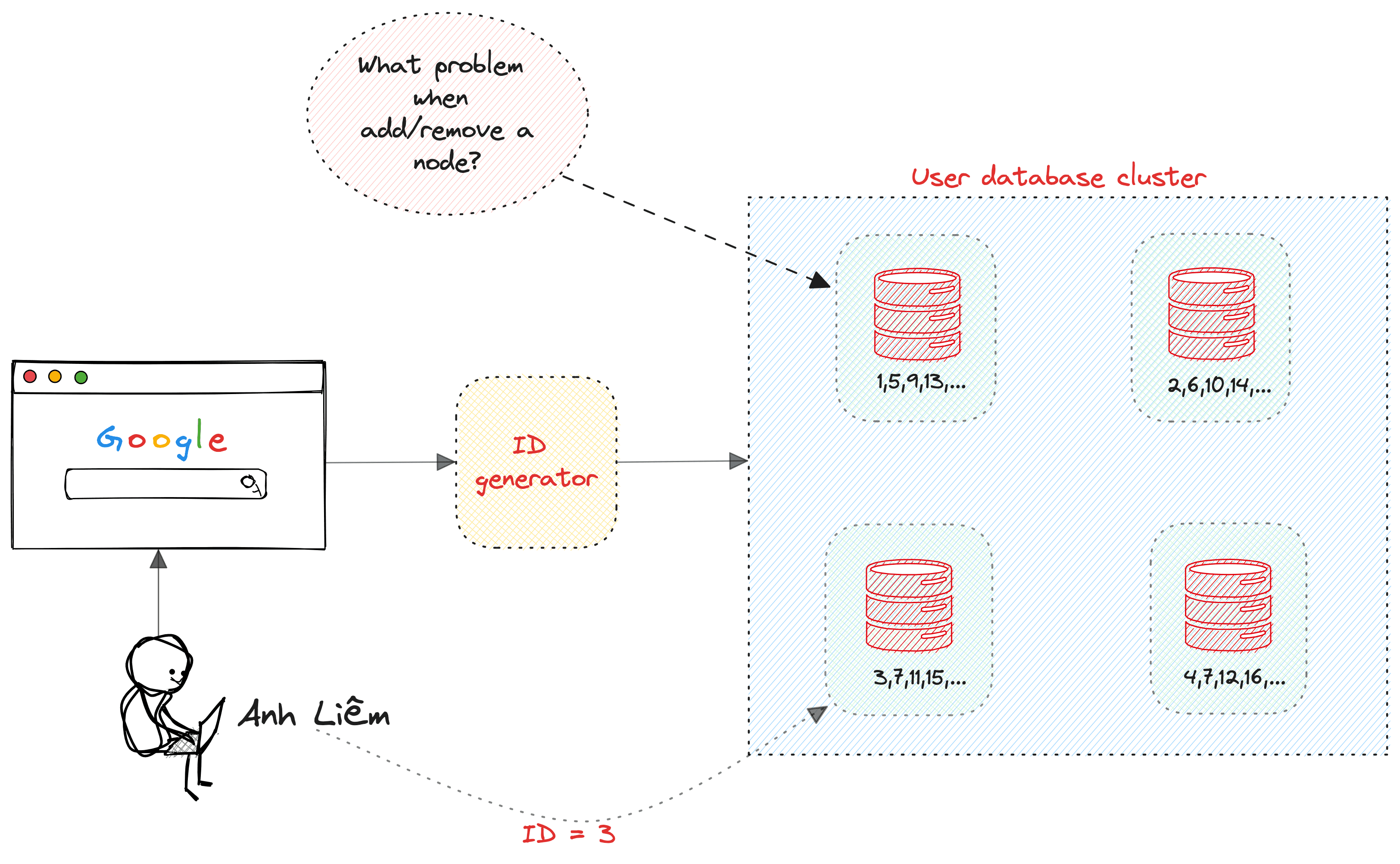
Bây giờ, vấn đề làm sao để generate ID cho user khi họ register đây ta? Làm sao biết user nào lưu vào database nào? Đây là ID Generator ở trong hình đó bạn
Bạn lại trằn trọc suy nghĩ, vì bạn là thiên tài nên sau 1 đêm bạn đã suy nghĩ ra là. À hay là mình tạo ra một hash function để hash user email lại và generate ID ra ta.
Và ý tưởng của bạn như sau (code dưới là ví dụ thôi nhoa):
class IdGenerator {
// Method này dùng để sinh ra một unique ID ứng với email của user.
public static int generateUserId(String email)
throws NoSuchAlgorithmException {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hashBytes = digest.digest(
email.getBytes(StandardCharsets.UTF_8));
return Math.abs(new BigInteger(1, hashBytes).intValue());
}
// Method này dùng để get server ID.
// Từ đó sẽ biết user nào cần được lưu trữ ở đâu.
public static int generateServerId(int userId) {
return userId % 4;
}
}Bây giờ khi user đăng ký tài khoản, bạn chỉ cần lấy email của user rồi đưa vào IdGenerator là xong.
// Giả sử email đang là "anhLiem@gmail.com";
int userId = IdGenerator.generateUserId(email); // Kết quả ra 16129187
int serverId = IdGenerator.generateServerId(userId); // Kết quả ra 3Vậy là bạn đã biết anh Liêm lưu ở server thứ 3.
Vậy bài toán đã được giải quyết rồi.
2000 years later!
Hệ thống của bạn chạy rất tốt, làm cho users rất hạnh phúc (bạn trở thành tỷ phú). Nhưng 2000 năm sau. Lượng user đã quá nhiều. Bạn muốn nâng cấp lên thành 10 node thay vì 4 node như 2000 năm trước. Á chà chà.
Bạn lại trằn trọc suy nghĩ sau hơn 2000 năm ngồi không lụm xiền.
Trong tích tắc bạn suy nghĩ ra được đáp án. Bây giờ bạn chỉ việc sửa lại chổ generateServerId thôi là xong chứ gì. Giờ sẽ chia cho 10.
// Sửa 4 thành 10 là xong ngay.
public static int generateServerId(int userId) {
return userId % 10;
}Ấy nhưng mà khoan. Hồi nảy anh Liêm đang được lưu ở server thứ 3 (Bạn còn nhớ ID của anh Liêm là 16129187 không). Fan guộc anh không bao giờ quên nên đã luôn nhớ về con số ID trên.
Và khi bạn upgrade hệ thống lên 10 con database. Và thông báo khoe với khách hàng là:
“Anh em ơi mau vào xem hệ thống bên tôi bây giờ mạnh lắm, tôi mới tăng thêm mấy chục con server siêu mạnh, latency dưới 50ms (thật ra đang chém)”. Ái chà chà.
Và đương nhiên Fan anh Liêm vào xem profile thì…NOT FOUND. What the….
Và bạn bị chửi tối tăm mặt mũi. Và rồi bạn chợt nhớ ra. Anh Liêm vẫn đang ở server 3. Nhưng ghi generateServerId với userId của anh Liêm thì ra 7 (tức là server số 7).
Bạn mới tá hỏa và cho anh em dev team thực hiện một cuộc đại migrate tất cả dữ liệu từ 4 node cũ sang 10 node mới. Sau đó bạn hết bị chửi và mới thở…phù nhẹ nhõm được.
Qua câu chuyện mình bịa ra ở trên đã cho bạn một cái nhìn tổng quan hơn về distributed database, ID generator, hay việc thêm note vào một cluster có sẵn.
Note: Hẹn gặp các bạn ở bài khác đi sâu hơn về các chủ đề ở trên như Snowflake (ID generator nổi tiếng), consistent hashing (giải thuật thay thế mod ở trên), ….
Bài cũng khá dài rồi, tới đây thôi nha các bạn. Hẹn gặp các bạn phần tiếp theo của bài này với các từ mới khác.